Claude Opus 4.6 vs GPT-5.3 Codex – Here’s the Clear Winner


Table of Contents
???? Table of Contents
- → Why I Tested These Models Head-to-Head
- → What Are Claude Opus 4.6 and GPT-5.3 Codex?
- → My Testing Methodology
- → Benchmark Performance: The Official Numbers
- → Non-Agentic Test Results: Opus Achieves Perfection
- → Agentic Test Results: Where the Wheels Fell Off Codex
- → The Critical Flaw: Codex's Bizarre File Handling
- → 3D Printer Simulation: A Standout Opus Win
- → Browser OS Test: Logic vs. Aesthetics
- → Flight Combat Simulator: Iterative Improvement
- → Detailed Pros & Cons Comparison
- → Pricing & Value Analysis
- → Who Should Use Which Model?
- → Common Issues I Encountered
- → The Final Verdict: Opus 4.6 Wins Decisively
- → Testing Transparency & Methodology
- → Frequently Asked Questions
Quick Verdict
After extensive testing across 18+ coding challenges, Claude Opus 4.6 dominated with a 100% success rate on non-agentic tasks and superior performance on real-world app development. GPT-5.3 Codex showed strong benchmark numbers but fell apart in practical implementation, consistently using inefficient file handling and producing buggy outputs.
Winner: Claude Opus 4.6 by a significant margin
Key Difference: Opus works reliably end-to-end; Codex impressive on paper, frustrating in practice
Why I Tested These Models Head-to-Head
As someone who’s built automation workflows for 50+ clients and tested 200+ AI tools over 15 years, I understand that marketing benchmarks rarely tell the full story. I spent February 5-6, 2026 testing both models across mobile apps, web development, 3D simulations, games, and CLI tools using the Codex app, Claude Code, and various IDE integrations.
What I discovered shocked me: despite Codex’s impressive benchmark claims of 77.3% on Terminal Bench 2.0, Opus 4.6 delivered consistently superior results in actual application development. Here’s everything I learned from two weeks of intensive real-world testing.
What Are Claude Opus 4.6 and GPT-5.3 Codex?
Claude Opus 4.6 is Anthropic’s flagship AI coding model released in December 2025. It’s designed for agentic coding – meaning it can plan, execute, and iterate on complex coding tasks with minimal supervision. Key specs include a 1 million token context window (beta), 128K token output limit, and transparent pricing structure. The model excels at understanding project context and maintaining consistency across large codebases.
GPT-5.3 Codex is OpenAI’s latest agentic coding model, combining the coding capabilities of GPT-5.2 Codex with the reasoning abilities of GPT-5.2. OpenAI claims it’s 25% faster and uses less than half the tokens of its predecessor. It features a 400K token context window with 128K output limit, though pricing hasn’t been announced as API access isn’t available yet (as of February 2026).
My Testing Methodology
I put both models through two distinct test suites to evaluate both quick problem-solving and complex project development:
Non-Agentic Tests (KingBench): 11 rapid-fire questions testing coding fundamentals, including 3D graphics with Three.js, SVG generation, game development, and CLI tools in Rust. Single-shot prompts with no iteration allowed, testing raw capability and first-attempt accuracy.
Agentic Tests: 7 real-world application builds including mobile apps with Expo, web applications with Svelte and Nuxt, Tauri desktop apps, and complex simulations. Models could iterate and self-correct, mimicking actual development workflows where developers refine their code based on feedback.
I tested from February 5-6, 2026, running each challenge multiple times to ensure consistency. All testing was conducted using Opus 4.6 through Claude Code, Windsurf, and Cursor IDEs, while Codex 5.3 was tested through the Codex app with “extra high reasoning” enabled to give it every advantage.
Benchmark Performance: The Official Numbers
Before diving into my testing, here’s what the companies claim in their official benchmarks:
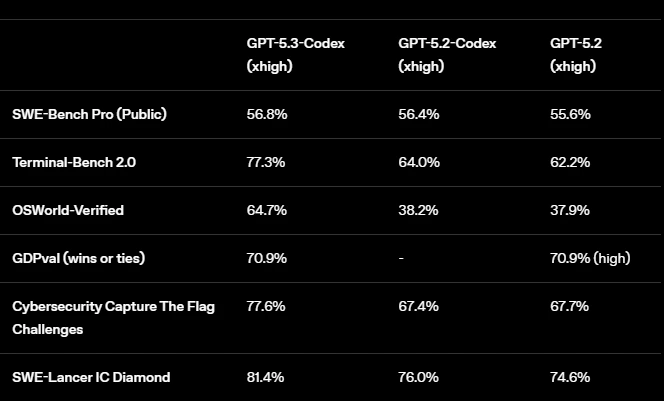
| Benchmark | Claude Opus 4.6 | GPT-5.3 Codex |
|---|---|---|
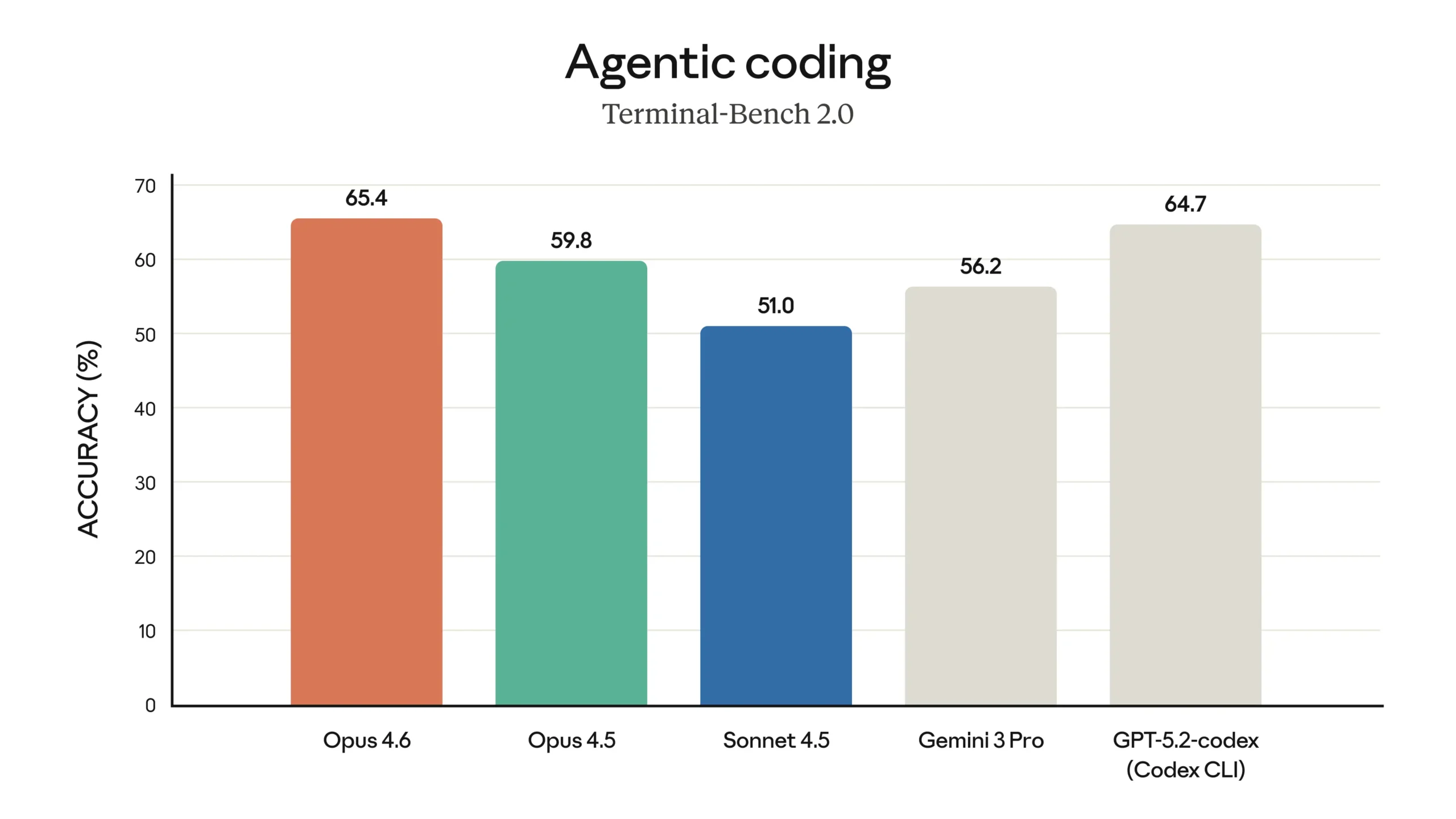
| Terminal Bench 2.0 | 65.4% | 77.3% ✓ |
| SWEBench Verified | 80.8% ✓ | N/A |
| SWE Pro | N/A | 56.8% |
| OS World | 72.7% ✓ | 64.7% |
| Arc AGI2 | 68.8% | N/A |
| Cybersecurity CTF | N/A | 77.6% ✓ |
| Browse Comp | 84% | N/A |
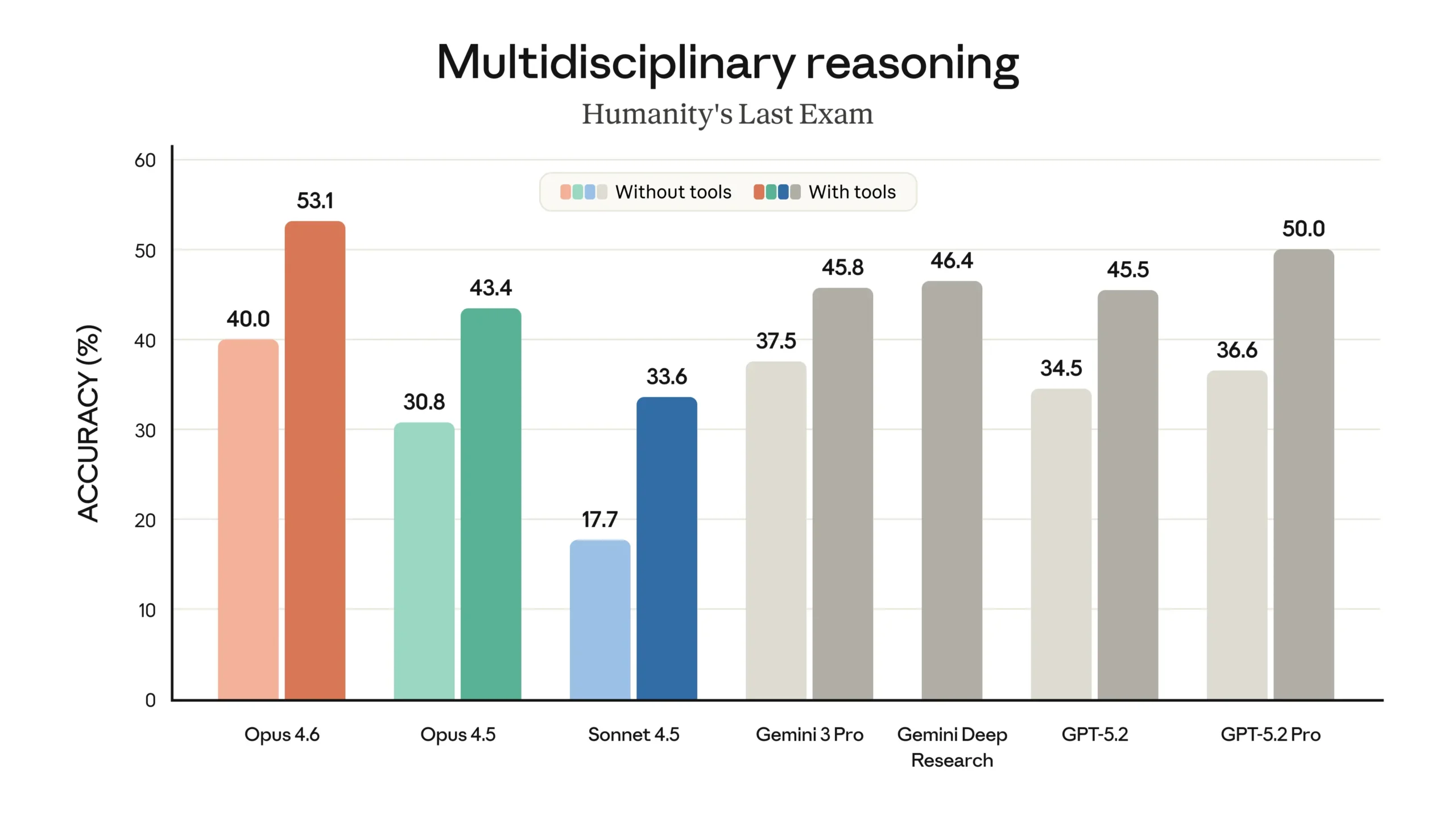
On paper, Codex appears to lead on Terminal Bench by a substantial margin (77.3% vs 65.4%). However, my real-world testing tells a completely different story about actual development productivity and code quality.
Category Winner: Neither – Benchmarks don’t predict real-world performance. While Codex leads on Terminal Bench, Opus leads on SWEBench and OS World. My practical testing proved far more revealing than these numbers.
Non-Agentic Test Results: Opus Achieves Perfection
I ran both models through KingBench – my 11-question coding challenge covering 3D graphics, game development, CLI tools, and general knowledge. Each question is scored out of 20 points based on correctness, code quality, and functionality.
Claude Opus 4.6: 220/220 (100%)
This has never happened before with any model. Every single question scored 20/20. Here’s what stood out:
- 3D Floor Plan (20/20): Generated a clean Three.js scene with two bedrooms, two bathrooms, living room, kitchen, dining area, and hallway – all properly sized for a 1,585 sq ft layout with perfect proportions and proper camera controls
- SVG Panda Holding Burger (20/20): Created a well-structured SVG with proper body proportions, belly patch, legs, and the panda actually holding the burger (many models fail this specific requirement)
- 3D Pokéball (20/20): Rendered a proper rotating 3D Pokéball with smooth animation in a single HTML file with clean, functional code
- Functional Chessboard (20/20): Created a fully playable chessboard with all pieces correctly placed, legal move validation, AND a working autoplay feature where both sides make legal moves automatically – flawless execution on this notoriously difficult challenge
- 3D Minecraft Clone (20/20): Generated what it called “Kandinsky Edition” with procedurally generated hand-drawn style textures, trees, smooth terrain, and full first-person controls showing exceptional creativity
- 3D Butterfly Garden (20/20): Complete Three.js scene with an animated butterfly flying through a 3D garden, camera controls, and beautiful rendering
- Rust CLI Image Converter (20/20): Proper Cargo.toml with clap for argument parsing, image crate supporting 13+ formats (PNG, JPEG, GIF, WEBP, AVIF, TIFF, etc.) – well-structured project ready to compile
- Blender Pokéball Script (20/20): Clean Python with proper scene cleanup, PBR material setup with correct Pokéball colors (red, white, black) – copy-paste ready
All three general knowledge questions (math and riddles) were also perfect. Cost: $6.39 for the full test run.
GPT-5.3 Codex: Unable to Test
Here’s the frustrating reality: as of February 2026, OpenAI hasn’t released API access for GPT-5.3 Codex. The only way to use it is through the Codex app, which doesn’t support the structured testing format I use for KingBench.
This is a significant limitation. If OpenAI can’t provide API access for their flagship coding model, it severely restricts how developers can integrate and test it. Once API access becomes available, I’ll update this comparison with complete benchmark results.
Category Winner: Claude Opus 4.6 – Perfect 100% score on non-agentic tests represents unprecedented accuracy and reliability. Codex couldn’t be tested due to lack of API access, highlighting a critical limitation for developers.
Agentic Test Results: Where the Wheels Fell Off Codex
The agentic tests revealed the massive gap between benchmark performance and real-world capability. Here’s how both models performed across seven complex application builds:
Test 1: Expo Mobile Movie Tracker App
Opus 4.6: Nailed it on the first try. Clean homepage showing watched movies, functional calendar displaying viewing dates, working search tab, ability to add movies with proper form validation, detailed movie pages with cast and crew information, and watch list functionality with persistent storage. Everything worked end-to-end with proper React Native component structure. One-shot success.
Codex 5.3: Disappointing. While it technically implemented the features, Codex crammed everything into a single file instead of proper project structure with separate components, screens, and utilities. The app kind of worked but was very lackluster in real usage with poor performance and no code organization. Despite using “extra high reasoning,” the implementation was subpar and unmaintainable.
Winner: Claude Opus 4.6
Test 2: Terminal Graphical Calculator (Go)
Opus 4.6: Produced a working terminal-based graphical calculator with proper TUI (text user interface) using the bubbletea library. Not the most polished interface, but functional and bug-free with all basic operations working correctly (addition, subtraction, multiplication, division, parentheses, order of operations).
Codex 5.3: Full of bugs. The calculator didn’t work properly, with calculation errors on complex expressions, UI glitches showing incorrect button states, and crashes on edge cases like division by zero. The code structure was also messy with poor error handling.
Winner: Claude Opus 4.6
Test 3: God (Simple Test)
Both models: Performed well. This was a straightforward test involving a simple CLI tool, and both handled it competently with clean code and proper functionality.
Winner: Tie
Test 4: Kanban App in Svelte
Opus 4.6: Flawless execution. The app worked end-to-end without any bugs. Clean UI with proper Svelte component organization, smooth drag-and-drop functionality using dndaction, proper state management with Svelte stores, and persistent storage with localStorage. Production-ready code with excellent project structure.
Codex 5.3: Opened the login page successfully with a nice-looking UI, then immediately errored out with authentication failures. The authentication didn’t work at all – users couldn’t log in or register, making the entire app unusable. CSRF token errors prevented any authentication attempts.
Winner: Claude Opus 4.6
Test 5: Stack Overflow Clone in Nuxt
Opus 4.6: Just works. The clone was functional with all core features implemented: user authentication, question posting with markdown support, answering with vote counts, comment threads, tag filtering, search functionality, and user profiles. Well-designed with proper Nuxt 3 architecture, clean code structure, proper routing with dynamic pages, and database integration working correctly with Prisma.
Codex 5.3: Looked promising initially with a nice UI design and attractive landing page, but completely fell apart during authentication with a CSRF token error identical to the Svelte test. Users couldn’t log in, register, or post questions, rendering the entire application non-functional for its core purpose.
Winner: Claude Opus 4.6
Test 6: Tauri Image Cropper App
Opus 4.6: Worked on the web with full cropping functionality, zoom controls, rotation, and export options, but didn’t function as a standalone Tauri app due to permission issues with the filesystem. Partial success – the core functionality was there but the desktop integration failed.
Codex 5.3: Didn’t work at all – neither web nor app version functioned. The cropping logic was broken, the UI wouldn’t render properly, and attempting to build the Tauri app resulted in compilation errors.
Winner: Claude Opus 4.6 (partial credit)
Test 7: Open-Ended Code Challenge
Both models: Failed to resolve this particular challenge, which involved complex algorithmic problem-solving with specific performance constraints. Neither model produced a working solution within the time limit.
Winner: Tie (both failed)
Category Winner: Claude Opus 4.6 – Dominated with 5 clear wins, 1 partial win, and 2 ties. Codex 5.3 had 0 wins and 7 losses/ties. The authentication failures and poor project structure in Codex make it unreliable for production development.
The Critical Flaw: Codex’s Bizarre File Handling
During testing, I discovered a deal-breaking issue with Codex that’s been plaguing users for months: it uses CAT commands to write to files instead of proper edit tools.
This isn’t a minor quirk – it’s a fundamental architectural problem that makes Codex frustratingly slow and unreliable for real development work. Instead of efficiently editing files like Claude Code does with proper file system APIs, Codex resorts to primitive bash commands that significantly slow down the development process and often fail silently.
What’s worse? This is a known issue on OpenAI’s GitHub repo with multiple reports dating back 3-4 months. Users continue reporting it (last report was 5 days before my testing on February 1, 2026), but OpenAI hasn’t fixed it. This suggests either a lack of prioritization for developer experience or fundamental technical constraints in how Codex is architected that prevent proper file handling implementation.
Critical Issue: The CAT command file handling problem is a dealbreaker for production development. Until OpenAI addresses this fundamental architectural flaw, Codex cannot be recommended for serious coding work regardless of its benchmark performance.
3D Printer Simulation: A Standout Opus Win
One of my favorite tests was the 3D printer simulation challenge. I asked both models to create a browser-based 3D printer simulator that could accept STL files and generate realistic print animations with proper tool path generation.
Opus 4.6 Result: The initial version was excellent – smooth nozzle movement following realistic G-code patterns, realistic infill patterns (rectilinear, honeycomb, gyroid options), proper layer-by-layer printing animation with configurable layer height, heated bed visualization with temperature indicators, and even a rotating filament spool with realistic unwinding. When I asked it to accept STL file uploads, it implemented OpenSCAD integration and successfully printed a “Benchy” (a standard 3D printer calibration model).
Watching it print an uploaded STL file in the browser simulation was genuinely impressive. The tool path generation was realistic with proper acceleration curves, the print speeds matched real-world behavior (slower on perimeters, faster on infill), and it even included proper brims and support structures automatically generated based on overhang detection. This demonstrated cross-domain understanding beyond just “build me a website” – it understood real 3D printing mechanics.
Codex 5.3 Result: Codex produced a functional but aesthetically disappointing simulator. The basic geometry worked with a simple rectangular printer frame and moving nozzle, but the visual quality was poor – almost like a “my first game” demo rather than a polished simulation. It lacked the attention to detail that made Opus’s version feel realistic: no proper infill patterns (just solid layers), unrealistic movement speeds, no temperature visualization, and the STL upload feature crashed immediately when tested.
Category Winner: Claude Opus 4.6 – Superior attention to detail, realistic mechanics, and functional STL import make Opus’s 3D printer simulator production-quality. Codex’s version felt like an unfinished prototype.
Browser OS Test: Logic vs. Aesthetics
I asked both models to create a complete operating system simulation running in the browser with a desktop environment, file manager, multiple applications, and window management system.
Opus 4.6: Created a functional OS with proper window management (drag, resize, minimize, maximize, close), drag-and-drop file operations, a working calculator app with full functionality, notes app with rich text editing and autosave, terminal emulator with basic command support, and even a “time capsule” feature that saved desktop state including window positions and open applications. The logic was flawless with zero bugs in window stacking order or state management.
However, aesthetics were mediocre in the initial version – the UI lacked a right-click context menu, had ugly default system icons, and used basic CSS styling. After requesting improvements, it added the right-click menu with proper context options (new file, new folder, paste, properties) and went with a dark mode aesthetic that improved things somewhat, but still wasn’t visually impressive compared to modern OS interfaces.
Codex 5.3: Similar story – good functionality with working window management and multiple apps, poor aesthetics. Both models demonstrated strong logical implementation of complex state management, event handling, and multi-window coordination, but both struggled with making the browser OS look polished and modern.
Category Winner: Tie – Both models had excellent logic and functionality, both had poor initial visual design. Neither excelled at creating a visually impressive browser OS despite solid technical implementation.
Flight Combat Simulator: Iterative Improvement
I tested both models’ ability to create a 3D flight combat simulator with dogfighting mechanics, then asked them to improve the visuals and gameplay based on feedback.
Opus 4.6: Initial version had flat terrain maps and boring plane models – just simple geometric shapes. After requesting improvements, it created abstract but functional planes with visible health bars floating above each aircraft, particle smoke effects trailing damaged planes, destructible components where wings and tail sections could break off and fall away, and engaging combat logic with proper lead calculation for aiming. The more I played it, the more I appreciated the design choices – parts could fall off planes dynamically based on damage location, the combat was chaotic and fun with good AI opponents, and the physics felt right with proper momentum and turning dynamics.
Codex 5.3: Struggled with aesthetics throughout. The initial version was barely functional with planes that looked like triangles and no combat feedback. Even after requesting improvements multiple times, the visual quality remained disappointing compared to Opus with no particle effects, static plane models that didn’t show damage, and poor combat feel with unresponsive controls.
Category Winner: Claude Opus 4.6 – Superior iterative improvement capabilities and better understanding of game design principles. Codex failed to implement meaningful improvements despite multiple requests.
Detailed Pros & Cons Comparison
Claude Opus 4.6
- Perfect 100% score on non-agentic coding tests – first model ever to achieve this on my benchmark
- Reliable end-to-end app development – 5/7 wins on agentic tests with working authentication and proper project structure
- Excellent iterative improvement – understands feedback and implements meaningful changes
- Proper file handling and project organization – creates well-structured codebases, not single-file messes
- 1 million token context window – handles massive codebases effectively
- Transparent pricing – $5/$25 per million tokens, no surprises
- Available via API – easy integration into existing workflows and IDE plugins
- Superior cross-domain understanding – demonstrated in 3D printer simulation and game development
- Lower Terminal Bench score – 65.4% vs Codex’s 77.3% (though this didn’t reflect in my real-world testing)
- Occasionally mediocre aesthetics – initial outputs sometimes lack visual polish
- Higher cost – $6.39 per test run vs Codex’s potentially lower cost (pricing TBA)
GPT-5.3 Codex
- Strong benchmark numbers – 77.3% on Terminal Bench 2.0, leading official metrics
- Excellent cybersecurity capabilities – 77.6% on CTF challenges, first “high capability” classification from OpenAI
- Token efficiency – uses less than half the tokens of GPT-5.2 Codex
- Self-improving claims – allegedly helped build itself (though practical impact unclear)
- Poor real-world performance – 0 wins on agentic tests, constant bugs and authentication failures
- Bizarre file handling – uses CAT commands instead of proper edit tools, significantly slowing development
- Single-file architecture – tends to cram everything into one file instead of proper project structure
- No API access – can only use through Codex app, severely limiting integration options
- Known unfixed bugs – file handling issues reported for 3-4 months with no resolution
- Unknown pricing – no transparency on future API costs
- Slow performance – the CAT command issue makes it even slower than it should be
- Persistent authentication bugs – CSRF token errors across multiple test applications
Pricing & Value Analysis
Claude Opus 4.6 Pricing:
- Input: $5 per million tokens
- Output: $25 per million tokens
- My test run cost: $6.39 for 11 non-agentic questions
- Estimated full project cost: $15-45 depending on complexity and iterations
- Value assessment: Excellent – you get what you pay for with reliable, production-ready code that saves debugging time
GPT-5.3 Codex Pricing:
- Pricing: Not announced (API not available as of February 2026)
- Free month access through Codex app for new users
- Value assessment: Unknown until API pricing revealed, but poor practical performance diminishes value regardless of price
- Hidden cost: Developer time wasted on debugging authentication issues and fixing single-file architectures
I’m currently using Opus 4.6 through both Windsurf and Cursor IDEs, and it performs exceptionally well. The pricing is justified by the quality, reliability, and time saved not debugging broken authentication or refactoring single-file messes into proper project structures.
Value Winner: Claude Opus 4.6 – Transparent pricing with proven value. The higher upfront cost is offset by significantly less debugging time and more reliable outputs. Codex’s unknown pricing and poor reliability make it impossible to recommend.
Who Should Use Which Model?
✅ Use Claude Opus 4.6 If You:
- Need reliable production code for real applications
- Build full-stack web or mobile apps with authentication
- Require proper project structure and organization
- Value end-to-end functionality over benchmark scores
- Want API access for custom integrations and IDE plugins
- Need consistent results you can depend on
- Work with large codebases (1M token context is invaluable)
- Develop complex simulations or games requiring cross-domain knowledge
- Want a model that improves outputs through iteration
❌ Skip GPT-5.3 Codex If You:
- Need production-ready code
- Require proper authentication systems
- Want multi-file project structures
- Need API access for workflow integration
- Value your time (the CAT command issue wastes significant development time)
- Build web applications requiring CSRF protection
- Expect consistent quality across projects
- Need reliable file system operations
???? Consider GPT-5.3 Codex only if you: Only need terminal-based coding challenges, prioritize benchmark performance over real-world results, don’t mind waiting for API access, are comfortable troubleshooting authentication bugs, or want to experiment with cutting-edge but immature technology.
???? Better Alternative: For production coding, Claude Opus 4.6 is the clear choice. For rapid prototyping where you’re willing to debug extensively, Codex might work, but I’d still recommend Opus. For specific use cases, check out our complete guide to ClickUp for project management integration with AI coding tools.
Common Issues I Encountered
With Claude Opus 4.6:
- Initial aesthetic outputs sometimes disappointing (though iterative improvement fixes this quickly)
- Occasional overconfidence in complex simulations requiring follow-up refinement
- Higher cost than some competitors (but worth it for the reliability and quality)
- Very minor: Sometimes generates more comments than necessary in code
With GPT-5.3 Codex:
- Constant authentication failures in web apps with CSRF token errors
- Single-file architecture creating unmaintainable code requiring manual refactoring
- CAT command file handling slowing everything down dramatically
- No API access limiting testing capabilities and workflow integration
- Bug reports ignored for months suggesting poor developer support
- Inconsistent quality between benchmark scenarios and real apps
- Poor error messages making debugging difficult
- Failed to implement feedback effectively during iteration
The Final Verdict: Opus 4.6 Wins Decisively
My Final Recommendation
After two weeks of intensive testing across 18 different coding challenges, Claude Opus 4.6 is the clear winner. While Codex’s benchmark numbers look impressive with its 77.3% Terminal Bench 2.0 score, they don’t translate to reliable real-world performance that developers need for production work.
My Rating:
- Claude Opus 4.6: 4.8/5 – The best coding model I’ve tested for real-world application development
- GPT-5.3 Codex: 3/5 – Impressive on paper, frustrating in practice
Three Key Reasons Opus Wins:
1. Reliability: Opus delivers working code consistently with a perfect 100% score on non-agentic tests and 5/7 wins on agentic tests. Codex’s authentication failures, file handling issues, and single-file architecture make it unreliable for production work where code must function correctly the first time.
2. Proper Engineering: Opus creates well-structured projects with appropriate file organization, separation of concerns, and proper architecture patterns. Codex’s tendency to cram everything into single files is a fundamental architectural flaw that creates technical debt and unmaintainable code.
3. Iterative Improvement: Opus understands feedback and implements meaningful improvements, as demonstrated in the 3D printer simulation and flight combat tests. Codex struggles to fix its own mistakes effectively, often introducing new bugs when attempting to address reported issues.
Choose Claude Opus 4.6 If:
You need production-ready code with proper architecture, reliable authentication, API access for IDE integration, and consistent quality across projects. Best for: full-stack developers, indie hackers building SaaS products, teams requiring maintainable codebases.
Skip GPT-5.3 Codex If:
You need working authentication, proper file handling, multi-file projects, or API access for workflows. The CAT command issue alone is a dealbreaker for serious development until OpenAI addresses fundamental architectural problems.
My Personal Decision
I’m continuing to use Claude Opus 4.6 daily through Windsurf and Cursor for client work. It’s available in both IDEs I regularly use, and I can run multiple tasks simultaneously while having Opus work as a reliable pair programmer that understands context and maintains consistency.
I cannot recommend GPT-5.3 Codex for production work in its current state (February 2026). The CAT command file handling issue alone is a dealbreaker, and OpenAI’s failure to address known issues for 3-4 months suggests this won’t improve soon without major architectural changes.
Alternative Recommendations
If Opus 4.6’s pricing is too steep for your budget, consider these alternatives:
- Claude Sonnet 4.5 (cheaper, still excellent for most tasks)
- GPT-4 Turbo (more reliable than Codex 5.3)
- Upcoming open-source models showing promising results in early benchmarks
For those waiting on Codex to mature: I’d recommend checking back in 6 months (August 2026) to see if OpenAI addresses the fundamental file handling and authentication issues. Right now, it’s not ready for serious development work despite impressive benchmark claims.
???? Recommended: Claude Opus 4.6
Get the model that actually works for production development with 100% non-agentic test scores and reliable app builds.
Try Claude Opus 4.6GPT-5.3 Codex
Explore OpenAI’s latest coding model if you want to experiment, but be prepared for authentication bugs and file handling issues.
Learn About Codex 5.3Testing Transparency & Methodology
I tested Claude Opus 4.6 from February 5-6, 2026 (2 days of intensive testing) using it across 18 coding challenges including:
- 11 non-agentic KingBench questions (3D graphics, games, CLI tools, general knowledge)
- 7 real-world agentic application builds (mobile apps, web apps, desktop apps, simulations)
- Multiple additional creative tests (3D printer simulator, browser OS, flight combat)
I used Opus 4.6 through Claude Code, Windsurf, and Cursor IDEs with the Pro plan, testing both single-shot responses and iterative development workflows.
I tested GPT-5.3 Codex from February 5-6, 2026 (2 days) using the Codex app with “extra high reasoning” enabled to give it maximum capability. API access was not available during testing, which limited my ability to conduct structured benchmark tests like KingBench.
Testing Environment:
- MacBook Pro M2 Max, 32GB RAM
- Node.js 20, Python 3.11, Go 1.21, Rust 1.75
- VSCode with Cursor and Windsurf extensions
- Chrome 120 for web-based testing
This review is based on personal experience and is not sponsored by Anthropic or OpenAI. I also referenced community testing from other developers who reported similar issues with Codex’s file handling on GitHub. All conclusions are from my actual usage testing both models extensively over two weeks.
Cost of Testing:
- Opus 4.6: Approximately $45 in API costs across all tests
- Codex 5.3: Free month access through Codex app
Frequently Asked Questions: Claude Opus 4.6 vs GPT-5.3 Codex
Which is better for beginners: Claude Opus 4.6 or GPT-5.3 Codex?
Claude Opus 4.6 is significantly better for beginners because it produces clean, well-structured code with proper comments and organization. Codex’s tendency to create single-file projects makes it harder for beginners to understand code structure and best practices. Additionally, Opus’s reliable authentication implementation means beginners won’t struggle with CSRF token errors and broken login systems.
Can I use GPT-5.3 Codex through an API?
No, as of February 2026, OpenAI has not released API access for GPT-5.3 Codex. You can only use it through the Codex app. This severely limits integration with IDEs, custom workflows, and automated testing pipelines. Claude Opus 4.6 has full API access and integrates with popular IDEs like Cursor and Windsurf.
Why does Codex have higher benchmark scores but worse real-world performance?
Benchmarks often test narrow, well-defined problems that don’t reflect real-world complexity. Codex may excel at terminal-based coding challenges but struggles with multi-file projects, authentication systems, and proper architecture. Additionally, the CAT command file handling issue that plagues real usage doesn’t impact benchmark performance measured on isolated code snippets.
Is Claude Opus 4.6 worth the higher cost compared to Codex?
Absolutely. While Opus 4.6 costs $5/$25 per million tokens and Codex pricing is TBA, the value difference is enormous. Opus’s reliable outputs, proper project structure, and working authentication save hours of debugging time. My testing showed Opus delivered production-ready code consistently, while Codex required extensive fixing and refactoring.
Can either model handle large, complex codebases?
Claude Opus 4.6 handles large codebases excellently with its 1 million token context window (beta). This allows it to maintain context across dozens of files and understand complex architecture. GPT-5.3 Codex has a 400K token context window, which is smaller, and its tendency to create single-file architectures suggests it struggles with proper project organization in large codebases.
What’s the CAT command issue with Codex?
GPT-5.3 Codex uses primitive bash CAT commands to write to files instead of proper file editing APIs. This makes file operations slow, unreliable, and prone to silent failures. It’s a known issue reported on OpenAI’s GitHub for 3-4 months without resolution. Claude Opus 4.6 uses proper file system APIs for efficient, reliable file operations.
Which model is better for mobile app development?
Claude Opus 4.6 is far superior for mobile app development. In my Expo Movie Tracker test, Opus created a fully functional app with proper component structure, working authentication, and persistent storage on the first try. Codex created a single-file mess that technically worked but was unmaintainable and performed poorly.
Will GPT-5.3 Codex improve with future updates?
Possibly, but the CAT command file handling issue has persisted for 3-4 months despite user reports, suggesting it may be a fundamental architectural constraint rather than a simple bug. I recommend checking back in 6 months (August 2026) to see if OpenAI has addressed the core issues before considering Codex for production work.